🤍
파이썬, 변수 여러 개의 값 입력받기
a, b = input().split() ---- 문자열 입력. 띄어쓰기로 구분.
a, b = map(int, input().split()) ---- 정수형 입력. 띄어쓰기로 구분.
num_list = list(map(int, input().split())) ---- 1차원 배열 입력(정수형 배로 저장)
s_list = [input() for _ in range(n)] ---- 문자열 n줄 입력받기. 엔터로 구분.
two_list = [list(map(int, input())) for _ in range(n)] ---- 띄어쓰기 없이 정수 n줄 입력. 2차원 배열로 저장.
t_list = [list(map(int, input().split)) for _ in range(n)] ---- 열은 띄어쓰기로, 행은 엔터로 구분하여 입력받아 2차원 배열로 저장.
input과 stdin
파이썬에서 input이나 print는 좀 무거운 함수. 따라서 input 대신 import sys 해서 sys.stdin.readline()을 사용하면 좋다.
단, input과 달리 stdin은 기본적으로 "\n"이 문자열 뒤에 포함되기 때문에 sys.stdin.readline().rstrip() 으로 "\n"을 제거해준다.
print는 sys.stdout.write(str() + "\n") 으로 바꾸면 더 빨라진다. 하지만 input에 비하면 print는 덜 느리기 때문에 그냥 써도 괜찮다.
해시 테이블(해시 맵)
: 키를 값에 mapping할 수 있는 구조인, 연관 배열 추상 자료형(ADT)를 구현하는 자료구조.(파이썬 딕셔너리)
대부분의 연산이 분할 상환 분석에 따른 시간 복잡도가 O(1)이다. 데이터의 양에 상관 없이 빠른 성능을 보임.
해시테이블의 삽입, 삭제, 탐색의 시간복잡도는 O(1).
해시 함수
: 임의 크기 데이터를 고정 크기 값으로 매핑하는 데 사용할 수 있는 함수.
ex. ABD => A1 1324BC => CB 해시함수로 2바이트의 고정크기 값으로 매핑함.
✅성능이 좋은 해시 함수들의 특징
- 해시 함수 값 충돌의 최소화 *충돌: 해싱 값이 동일하게 나오는 경우.
- 쉽고 빠른 연산
- 해시 테이블 전체에 해시 값이 균일하게 분포
- 사용할 키의 모든 정보를 이용하여 해싱
- 해시 테이블 사용 효율이 높을 것
충돌을 해결하는 두가지 방법

- 개별 체이닝: 위의 그림과 같이 충돌 발생 시 연결 리스트로 연결한다. 흔히 해시 테이블이라고 하는 것이 바로 이 방식.
원리)
1. 키의 해시 값을 계산한다.
2. 해시 값을 이용해 배열의 인덱스를 구한다.
3. 같은 인덱스가 있다면 연결 리스트로 연결한다.
잘 구현한다면 대부분의 탐색은 O(1)이지만, 최악의 경우(모든 해시 충돌이 발생)에는 O(n)이 된다.
- 오픈 어드레싱: 충돌이 일어나면 선형탐사(linear probing)를 통해 빈 공간을 찾아 할당. 이 경우, 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장이 없다.
*선형 탐사의 문제점: 해시 테이블에 저장되는 데이터들이 고르게 분포되지 않고 뭉치는 경향이 있음.
그리고 오픈 어드레싱 방식은 버킷 사이즈보다 큰 경우에는 삽입할 수 없으므로 일정공간 이상 채워지면, 더 큰 크기의 또다른 버킷을 생성하고 여기에 새롭게 복사하는 리해싱 과정이 일어남.
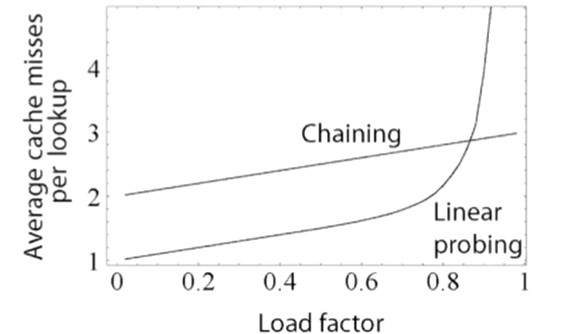
- 파이썬의 해시테이블은 오픈 어드레싱 방식으로 구현되어 있다. (해시테이블로 구현된 파이썬 자료형: 딕셔너리)
*모던 언어들은 오픈 어드레싱 방식을 채택해 성능을 높이는 대신, 로드 팩터를 작게 잡아 성능 저하 문제를 해결함.
개별 체이닝 방식은 link 오버헤드가 큰 것이 단점.
해싱
: 해시 테이블을 인덱싱하기 위해 해시 함수를 사용하는 것.
정보를 가능한 빠르게 저장하고 검색하기 위한 중요한 기법 중 하나.
✔️모듈러 연산: 나눗셈 연산. 가장 단순하면서도 널리 쓰이는 정수형 해싱 기법. h(x) = x mod m 여기서 x는 입력값, m은 해시 테이블의 크기이다. m은 일반적으로 2의 멱수(제곱수)에 가깝지 않은 소수를 선택하는 게 좋다.
로드 팩터(Load Factor)
: 해시 테이블에 저장된 데이터 개수 n을 버킷(저장공간)의 개수 k로 나눈 것. load factor = n / k
저장공간이 얼마나 점유되어있는지를 나타냄. 로드 팩터 비율에 따라서 해시 함수를 재작성해야 될지 테이블의 크기를 조정해야할 지 결정.
- 자바10의 경우 해시맵의 디폴트 로드 팩터는 0.75이며 파이썬은 0.66.
- 일반적으로 로드 팩터가 증가할수록 해시 테이블 성능은 감소함. 0.75를 넘어설 경우 동적 배열처럼 해시 테이블의 공간을 재할당함. ex. 로드 팩터가 0.75라는 것은 공간 네 개 중 세 개가 찼다는 것, 따라서 공간을 12개로 늘려야겠다고 판단할 수 있음.
ALGORITHM CODE KATA
Ⅰ. 자연수 n이 매개변수로 주어집니다. n을 3진법 상에서 앞뒤로 뒤집은 후, 이를 다시 10진법으로 표현한 수를 return 하도록 solution 함수를 완성해주세요. (school.programmers.co.kr)
def solution(n):
ternary_n = []
answer = 0
while (n > 0):
ternary_n.append(n % 3)
n //= 3
if n == 0:
return 0
ternary_n.reverse()
for i in range(len(ternary_n)):
answer += ternary_n[i]*(3**i)
return answer
Ⅱ. 정수를 저장하는 스택을 구현한 다음, 입력으로 주어지는 명령을 처리하는 프로그램을 작성하시오. 명령은 총 다섯 가지이다. (acmicpc.net)
- push X: 정수 X를 스택에 넣는 연산이다.
- pop: 스택에서 가장 위에 있는 정수를 빼고, 그 수를 출력한다. 만약 스택에 들어있는 정수가 없는 경우에는 -1을 출력한다.
- size: 스택에 들어있는 정수의 개수를 출력한다.
- empty: 스택이 비어있으면 1, 아니면 0을 출력한다.
- top: 스택의 가장 위에 있는 정수를 출력한다. 만약 스택에 들어있는 정수가 없는 경우에는 -1을 출력한다.
stack = []
answer = []
def push(x):
stack.append(x)
def pop():
if empty():
return -1
else:
return stack.pop()
def size():
return len(stack)
def empty():
if len(stack)==0:
return 1
else:
return 0
def top():
if empty():
return -1
else:
return stack[-1]
N = int(input())
for i in range(N):
command = input().split()
if command[0] == 'push':
if len(command) > 1:
push(int(command[1]))
else:
print("Error: 'push' command requires a number.")
elif command[0] == 'pop':
answer.append(pop())
elif command[0] == 'size':
answer.append(size())
elif command[0] == 'empty':
answer.append(empty())
elif command[0] == 'top':
answer.append(top())
else:
print("Error: Unknown command.")
print('\n'.join(map(str, answer)))#입력
14
push 1
push 2
top
size
empty
pop
pop
pop
size
empty
pop
push 3
empty
top
#출력
>>> 2
2
0
2
1
-1
0
1
-1
0
3